
The AI industry is experiencing a profound shift in how computational resources are allocated and optimized. While the last decade saw rapid advances through massive pre-training efforts on repurposed GPUs, we’re now entering an era where test-time compute (TTC) and custom accelerators are emerging as the next frontier of AI advancement. As highlighted in recent industry developments, DeepSeek AI lab disrupted the market with a model that delivers high performance at a fraction of competitors’ costs, signaling two significant shifts: smaller labs producing state-of-the-art models and test-time compute becoming the next driver of AI progress.
The Shifting AI Landscape: From Training to Test-Time Compute
This evolution is driven by a fundamental constraint: the scarcity of additional training data. The major AI labs have already trained their models on much of the available public data (including many copyrighted works to which they had no legal claim to use), making further pre-training improvements increasingly limited. Instead, the focus is shifting to reasoning capabilities at inference time, where models “think” before responding to a question rather than simply generating the statistically most likely response [2].
Python is a Dead End, Not a Destination
The current dominant approach to AI model development, using dynamically typed frameworks like PyTorch, presents structural limitations to this pivot that become increasingly apparent as the AI landscape moves to a test-time compute paradigm. Python’s inherent limitations prevent “baked in” awareness of units of measure and other constraints that would naturally govern many classes of model behavior to a grounded result.
This absence of strong type safety leads to overtraining as developers attempt to compensate through brute force, teaching models to reflect an image of disciplined behavior rather than embedding principles at the foundation. The result is inefficient, computationally expensive inference that lacks “zero-cost” safeguards of a more structured approach that SpeakEZ offers with the Fidelity Framework.
The core issue is that today’s models are missing the structured understanding of the world and its physical constraints that humans develop naturally. Current AI approaches struggle to incorporate these constraints, resulting in systems that require enormous training datasets yet still fail to reliably perform tasks that humans learn quickly.
As Yann LeCun, Chief AI Scientist at Meta, noted: “A 17-year-old can learn to drive a car in about 20 hours of practice… And we have millions of hours of training data of people driving cars, but we still don’t have self-driving cars. So that means we’re missing something really, really big.”
SpeakEZ’s Fidelity Framework: A New Paradigm for Reliable AI
SpeakEZ’s Fidelity Framework represents a groundbreaking approach that addresses these fundamental limitations. The framework includes:
- Firefly compiler: Enables efficient native compilation through a direct F# to MLIR/LLVM path
- Farscape CLI: Provides seamless integration with verified C/C++ libraries
- BareWire interface: Delivers high-performance, low-burden binary communication
- Furnace auto-differentiation: Supports reliable machine learning operations
This constellation of technologies creates a principled foundation for high-trust AI deployment that combines correctness with high performance. And for those organizations interested in advanced certification, Fidelity also includes high-assurance capabilities through a bridge to the F*(F-star) verification framework that will be detailed in future technical publications.
The F# Advantage: Type Safety for Neural Representations
A cornerstone of SpeakEZ’s approach is F#’s long-standing sophisticated type system, which provides compile-time safety without runtime overhead [1]. This represents a fundamental shift from the current paradigm where models must learn constraints through extensive training rather than having these constraints built into their foundation. And it follows that even in model training the burden of runtime marshaling of tensor shapes conveys an outsized time and computational cost for current model building practices.
Consider how neural networks process data through tensor operations, where shape inconsistencies and dimensional mismatches are common sources of errors that can only be detected at runtime in Python-based frameworks. Though the use of F# and Furnace those runtime considerations are resolved before compilation even begins:
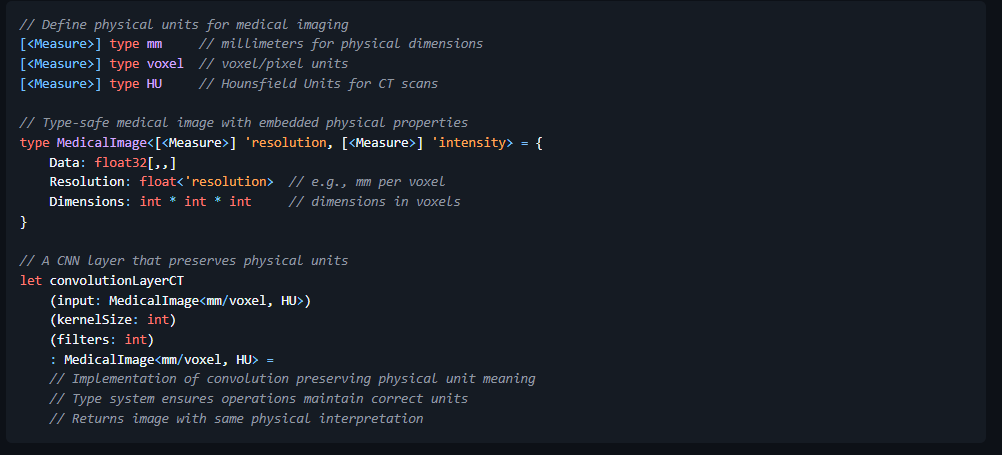
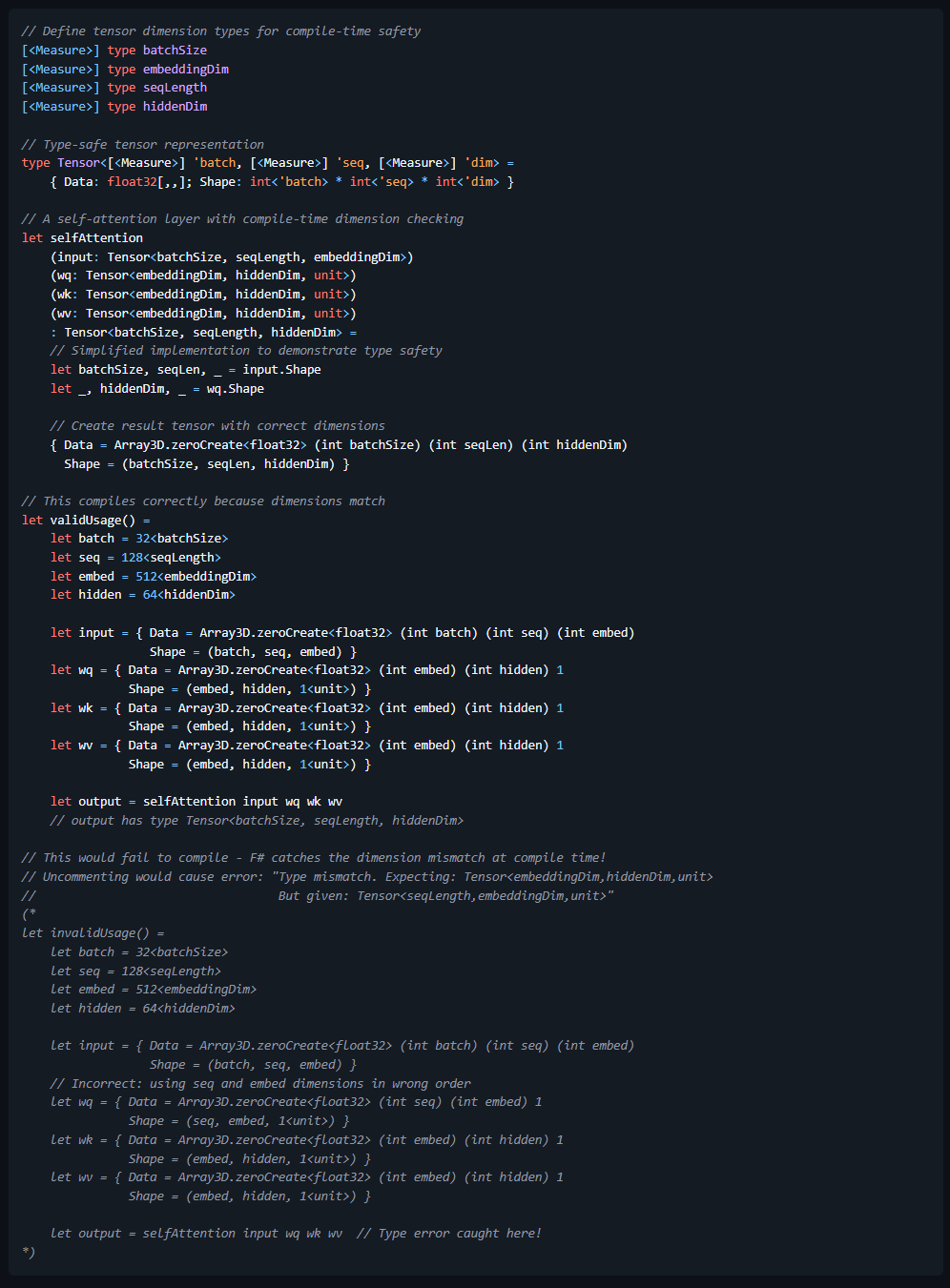
In both examples, the F# type system ensures that operations maintain dimensional and physical consistency at compile time. If a developer attempts to use incompatible dimensions or units, the F# tooling will notify the developer with a compilation error at design time. This provides a constructive constraint that supports correctness and safety that no other tooling stack can match. This collaborative approach between the tooling and developer eliminates an entire class of errors that plague deep learning systems and currently require extensive runtime checks, debugging, and trial-and-error. From this perspective, the efficiency gains of SpeakEZ’s Fidelity Framework also impacts design-time. Many machine learning working groups currently plan for large staff allocations over long calendar windows into the assumptions of their work. The efficiency gains that SpeakEZ claims over Python based frameworks are not just a “flex”. They’re a material advance in transforming the half-life of model engineering cycles and the outsized fixed costs that come with it.
This foundation creates a path toward rapidly delivering neural networks that can reason with built-in dimensional awareness and structural constraints, reducing the need to rediscover these patterns from training data alone. The benefits extend beyond just catching errors. By embedding structural knowledge directly into the type system, models built with the Fidelity Framework can potentially learn more efficiently from less data, as they don’t need to rediscover basic constraints that are already encoded in their foundation. This aligns with research into inductive biases in machine learning, where as noted in a Royal Society paper on higher-level cognition: “Our current state-of-the-art machine learning systems sometimes achieve good performance on a specific and narrow task, using very large quantities of labelled data” while systems with appropriate inductive biases can generalize more efficiently with less training data [7]. These cumulative advances: reduced error rate, simplified model processing, reduced data needs all converge on challenging the current assumptions on the outsized time and compute costs of building models. And in that process companies get higher performance, greater reliability, and more options for deploying high-leverage models in a wider array of devices that meet the customer and their needs “where they are”.
Multi-Head Latent Attention: A Case Study in Efficiency
The Fidelity Framework’s Furnace component demonstrates how to adapt cutting-edge techniques like DeepSeek’s Multi-Head Latent Attention (MLA) while tuning models for performance. MLA achieves remarkable efficiency improvements, up to a 93.3% reduction in KV cache size while simultaneously improving model throughput. [see the Appendix for an extended example]
This approach includes:
- Latent Compression Layer: To compress the input hidden states
- Query Projection: For computing query vectors
- Key/Value Decompression: To expand latent vectors to full key/value representations
- RoPE Handling: For decoupled positional encoding
- Forward Pass: The main attention computation logic
- KV Cache Management: For efficient caching of latent vectors
The primary benefit is the significant reduction in memory footprint during inference while maintaining or improving quality compared to standard attention mechanisms.Through the Fidelity Framework, MLA can be deployed across diverse hardware architectures through a unified MLIR lowering pipeline, including NVIDIA, AMD, and Tenstorrent hardware. This approach enables:
- Dramatic reduction in memory requirements
- Performance improvements over standard attention
- Increased token output while maintaining context
- Significantly expanded context windows without hardware upgrades
These benefits are delivered while maintaining memory safety and computational accuracy guarantees throughout the compilation process, something that would be difficult or impossible with conventional Python approaches.
“AI Refinery”: Optimizing Inference for the Real World
SpeakEZ’s vision of an “AI Refinery” represents a fundamental rethinking of how AI models should be constructed for optimal real-world performance. Like an oil refinery that transforms crude petroleum into valuable end products, the AI Refinery transforms raw model capabilities into verified, efficient, and safe computational systems.
By focusing on inference optimization through compile-time verification and F#’s inherent type safety, SpeakEZ addresses the emerging challenges in test-time compute [5]:
Memory Efficiency: F#’s units of measure and the framework’s optimized memory management significantly reduce the memory footprint of models during inference, enabling larger context windows and more complex reasoning on existing hardware. \
Computational Performance: Direct compilation to MLIR/LLVM creates highly optimized execution paths that deliver superior inference speed compared to interpreted approaches. \
Verification Guarantees: Unlike black-box models whose behaviors can only be validated through extensive testing, models built with the Fidelity Framework carry type guarantees and even algorithmic proofs of their properties and constraints. \
Hardware Adaptability: The framework’s universal adaptation interface enables targeting of diverse hardware architectures from a single verified codebase, maximizing performance across the computing ecosystem. \
An Optimal Path Forward: Physics-Based Models for AI You Can Bank On
The future of AI lies in models that incorporate real-world understanding and constraints at their foundation rather than attempting to approximate these principles through brute-force training [3]. Current AI models, despite their impressive capabilities in language and image generation, still fundamentally lack the ability to model and predict mathematical, financial and physical reality with the well-founded understanding that humans possess.
SpeakEZ’s Fidelity Framework embraces a vision for building models with intrinsic understanding of the problem space’s natural constraints through F#’s type system and formal verification. This approach aims to create systems that can reason about the physical world with the same natural understanding that humans develop, rather than approximating this understanding through massive datasets that continue to leave many models coming up short.
Conclusion: Redefining AI **Delivery **for the Age of Inference
As the AI landscape evolves from massive pre-training to the age of test-time compute [6], SpeakEZ’s Fidelity Framework offers a trusted solution that addresses the fundamental limitations of current approaches. By leveraging F#’s powerful type system and direct compilation pathways, SpeakEZ is creating an “AI Refinery” that transforms how models are built, verified, and deployed.
The result is a new generation of AI systems that combine advanced reasoning capabilities with formal safety and efficiency guarantees, delivering trusted, high-performance computation for mission-critical applications. Building on the F# ecosystem’s 20-year foundation of balancing computational efficiency with a supportive developer experience, SpeakEZ’s Fidelity Framework extends this paradigm into the next wave of AI innovation. As test-time inference increasingly drives AI advancement, SpeakEZ’s approach to safe and trustworthy compute will transform the dream of next-gen intelligent systems into commercial reality.
References
Microsoft Learn. “Units of Measure - F#.” 2024. https://learn.microsoft.com/en-us/dotnet/fsharp/language-reference/units-of-measure \
RCR Wireless. “The convergence of test-time inference scaling and edge AI.” February 2025. https://www.rcrwireless.com/20250210/ai-infrastructure/convergence-of-test-time-inference-scaling-and-edge-ai \
NVIDIA Developer Blog. “Physics-Informed Machine Learning Platform NVIDIA PhysicsNeMo Is Now Open Source.” March 2023. https://developer.nvidia.com/blog/physics-ml-platform-modulus-is-now-open-source/ \
F# for Fun and Profit. “Units of measure.” 2024. https://swlaschin.gitbook.io/fsharpforfunandprofit/understanding-f/understanding-fsharp-types/units-of-measure \
DZone. “Understanding Inference Time Compute.” January 2025. https://dzone.com/articles/understanding-inference-time-compute \
VE3 Global. “Inference-Time Scaling: The Next Frontier in AI Performance.” January 2025. https://www.ve3.global/inference-time-scaling-the-next-frontier-in-ai-performance/ \
Bengio, Y., et al. “Inductive biases for deep learning of higher-level cognition.” Proceedings of the Royal Society A: Mathematical, Physical and Engineering Sciences, 2021. https://royalsocietypublishing.org/doi/10.1098/rspa.2021.0068 \